Provisioning OpenSearch as Infrastructure as Code (IaC) and Securing Data Access with API Gateway and Lambda
6/25/2023, Published in Medium, DevTo and HashNode
1 min read
200
This blog is about Provisioning OpenSearch as Infrastructure as Code (IaC) and securing data access with API Gateway and Lambda allows you to automate the deployment and configuration of an OpenSearch cluster while ensuring secure access to the cluster's data through API Gateway and Lambda functions
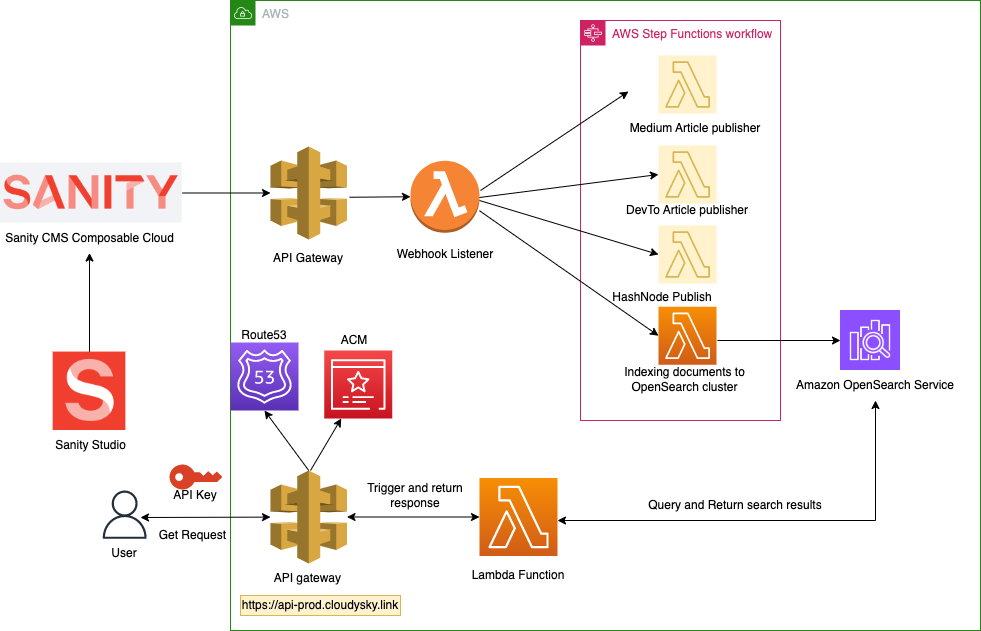
This blog is a continuation of my blog series on "How I built my Cloudysky portal from ground up using some of the modern tech stacks. Please have a look at the following blogs to get the overview of the architecture.
- How I built my Cloudsky portfolio and leveraged AWS services for infrastructure and automation ?
- Automating AWS Step Functions: Programmatically Initiating Workflows for Seamless Orchestration
In this blog, I will focus on provisioning OpenSearch as Infrastructure as Code (IaC) through CloudFormation Template automate the deployment and configuration of an OpenSearch cluster while ensuring secure access to the cluster's data through API Gateway and Lambda functions.
Provisioning OpenSearch Cluster
In this example, I will be using aws cli to provision OpenSearch Cluster with the CloudFormation template.
- Create a CloudFormation template in YAML or JSON format. This template will define your OpenSearch cluster's infrastructure.
- Include the necessary resources, such as an AWS::OpenSearchService::Domain resource, to provision the OpenSearch cluster.
- Configure the desired properties for the OpenSearch cluster, such as instance types, storage options, and network settings.
- Add any additional resources or configurations required for your specific use case.
Remember to review the OpenSearch EngineVersion you would be using. Also, review the charges for OpenSearch services to avoid unnecessary charges for the service usage. Also, as a best practice keep the Opensearch domain endpoint username and password secured. In this example, I have kept them in Secrets Manager for my reference only.
AWSTemplateFormatVersion: '2010-09-09'
Parameters:
DomainName:
Type: String
Description: A name for the Amazon OpenSearch domain
MasterUsername:
Type: String
Description: Master usernames must be between 1 and 16 characters.
MasterPassword:
Type: String
Description: Master password must be at least 8 characters long and contain at least one uppercase letter, one lowercase letter, one number, and one special character.
NoEcho: true
Resources:
OpenSearchServiceDomain:
Type: AWS::OpenSearchService::Domain
Properties:
DomainName: !Ref DomainName
EngineVersion: 'OpenSearch_2.3'
ClusterConfig:
DedicatedMasterEnabled: true
InstanceCount: '2'
ZoneAwarenessEnabled: true
InstanceType: 'r6g.large.search'
DedicatedMasterType: 'r6g.large.search'
DedicatedMasterCount: '3'
EBSOptions:
EBSEnabled: true
Iops: '0'
VolumeSize: '20'
VolumeType: 'gp2'
AccessPolicies:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
AWS: '*'
Action:
- 'es:*'
Resource: !Sub 'arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${DomainName}/*'
EncryptionAtRestOptions:
Enabled: true
NodeToNodeEncryptionOptions:
Enabled: true
DomainEndpointOptions:
EnforceHTTPS: true
AdvancedSecurityOptions:
Enabled: true
InternalUserDatabaseEnabled: true
MasterUserOptions:
MasterUserName: !Ref MasterUsername
MasterUserPassword: !Ref MasterPassword
MySecretMasterUsername:
Type: 'AWS::SecretsManager::Secret'
Properties:
Name: os-username
Description: Master username for Amazon Opensearch cluster
SecretString: !Ref MasterUsername
MySecretMasterPassword:
Type: 'AWS::SecretsManager::Secret'
Properties:
Name: os-password
Description: Master password for Amazon Opensearch cluster
SecretString: !Ref MasterPassword
Outputs:
DomainEndpoint:
Value: !GetAtt OpenSearchServiceDomain.DomainEndpointStep 1: Upload the CloudFormation Template to S3
- If you haven't already, create an S3 bucket where you can upload the CloudFormation template.
- Use the AWS CLI to upload the template file to your S3 bucket. For example:
aws s3 cp <local_template_file> s3://<your_bucket_name>/<template_file_name>
Step 2: Create the CloudFormation Stack
- Use the AWS CLI to create the CloudFormation stack, specifying the template URL and desired stack parameters. For example:
aws cloudformation create-stack --stack-name <stack_name> --template-url https://s3.amazonaws.com/<your_bucket_name>/<template_file_name> --parameters ParameterKey=<parameter_name>,ParameterValue=<parameter_value> --capabilities CAPABILITY_NAMED_IAM
- Replace <stack_name> with a unique name for your CloudFormation stack.
- Update the --template-url parameter with the appropriate URL for your S3 bucket and template file.
- Provide the necessary parameters and their values using the --parameters option. Adjust the parameters according to your CloudFormation template.
- Wait for the CloudFormation stack creation to complete. You can use the following command to check the stack status:
aws cloudformation describe-stacks --stack-name <stack_name> --query "Stacks[0].StackStatus"
Step 3: Access the Provisioned OpenSearch Cluster
- Once the stack creation is complete, use the AWS Management Console or AWS CLI to retrieve the endpoint URL of your provisioned OpenSearch cluster.
Data Ingestion into OpenSearch
In this example, I have used the sanity CMS data coming from webhook event to ingest into OpenSearch and based on your use case, you could modify it.
Here is a sample Lambda code that ingests data into OpenSearch Cluster.
- I found opensearch-py client library has good support to interact with Opensearch cluster in python.
- As a first step, you would connect to the OpenSearch domain endpoint using the client library using the secrets stored in SecretsManager and then perform insert and update operation conditionally.
import json
import boto3
from opensearchpy import OpenSearch, helpers
def lambda_handler(event, context):
domain_endpoint = "YOUR_OPENSEARCH_DOMAIN_ENDPOINT"
sanity_blog_playload = event['Payload']
sanity_blog_title = sanity_blog_playload['title']
sanity_blog_description = sanity_blog_playload['description']
sanity_blog_body = sanity_blog_playload['body']
sanity_blog_id = sanity_blog_playload['id']
sanity_blog_categories = sanity_blog_playload['categories']
sanity_blog_created_at = sanity_blog_playload['createdAt']
sanity_blog_updated_at = sanity_blog_playload['updatedAt']
categories = []
for category in sanity_blog_categories:
categories.append(category['title'])
sanity_cms_data = [
{
"id": sanity_blog_id,
"title": sanity_blog_title,
"description": sanity_blog_description,
"body": sanity_blog_body,
"categories": categories,
"createdAt": sanity_blog_created_at,
"updatedAt": sanity_blog_updated_at
}
]
# Get Secret from secret manager
def get_secrets(secret_name):
region_name = "us-east-1"
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=region_name
)
get_secret_value_response = client.get_secret_value(
SecretId=secret_name)
return get_secret_value_response
# Get connection string
def get_connection_string():
user = get_secrets(secret_name="os-username")['SecretString']
password = get_secrets(secret_name="os-password")['SecretString']
connection_string = "https://{}:{}@{}:443".format(
user, password, domain_endpoint)
return connection_string
# Insert Documents
def insert_documents(data, client, index):
def gendata():
for document in data:
id = document["id"]
yield {
"_id": id,
"_index": index,
"_source": document
}
response = helpers.bulk(client, gendata())
print("\nIndexing Documents")
print(response)
# update Document
def update_documents(connection_string, data, client):
def gendata():
for document in data:
index_id = document["id"]
# Delete 'id' column because we don't want to index it
yield {
"_op_type": "update",
"_id": index_id,
"_index": index,
"doc": document,
}
response = helpers.bulk(client, gendata(), request_timeout=60)
print('\nUpdating document')
print(response)
# Execution of the index data
connection_string = get_connection_string()
client = OpenSearch([connection_string])
# Search for the document
document_exists = client.exists(index=index, id=sanity_blog_id)
if document_exists:
print("Document already exists")
update_documents(connection_string, sanity_cms_data, client)
else:
print("Document does not exist")
insert_documents(sanity_cms_data, client, index)You can verify the data ingestion by logging into the OpenSearch domain endpoint URL.
Secure access to the cluster's data through API Gateway and Lambda functions
To access the data securely, you could use various strategies and the following uses API gateway and Lambda and this is used by my Cloudysky web app to make calls to OpenSearch to get search results.
Here is the CloudFormation template for the API gateway with custom route53 domain and also, uses API key to secure the API access. Also, it has the Lambda function resource which will used to search the data in OpenSearch cluster.
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
cloudysky-web-opensearch-api
Sample SAM Template for cloudysky-web-opensearch-api
# More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rst
Globals:
Function:
Timeout: 3
MemorySize: 128
Tracing: Active
Api:
TracingEnabled: true
Resources:
ApiCertificate:
Type: AWS::CertificateManager::Certificate
Properties:
DomainName: !Sub api-prod.cloudysky.link
ValidationMethod: DNS
ApiGatewayApi:
Type: AWS::Serverless::Api
Properties:
StageName: prod
Cors: "'*'"
Domain:
DomainName: !Sub CUSTOM_DOMAIN
CertificateArn: !Ref ApiCertificate
EndpointConfiguration: EDGE
Route53:
HostedZoneId: HOSTED_ZONE
Auth:
ApiKeyRequired: true # sets for all methods
UsagePlan:
CreateUsagePlan: PER_API
# Quota:
# Limit: 1000
# Period: DAY
# Throttle:
# RateLimit: 5
# CacheClusterEnabled: true
# CacheClusterSize: '0.5'
# MethodSettings:
# - ResourcePath: /search
# HttpMethod: GET
# CachingEnabled: true
# CacheTtlInSeconds: 300
OpenSearchAPIFunction:
Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction
Properties:
CodeUri: opensearch_api/
Handler: app.lambda_handler
Runtime: python3.9
Architectures:
- x86_64
Events:
OpenSearchAPI:
Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api
Properties:
Path: /search
Method: get
RestApiId:
Ref: ApiGatewayApi
Policies:
- AmazonOpenSearchServiceFullAccess
- CloudWatchPutMetricPolicy: {}
- SecretsManagerReadWrite
- AmazonSSMReadOnlyAccess
ApplicationResourceGroup:
Type: AWS::ResourceGroups::Group
Properties:
Name:
Fn::Join:
- ''
- - ApplicationInsights-SAM-
- Ref: AWS::StackName
ResourceQuery:
Type: CLOUDFORMATION_STACK_1_0
ApplicationInsightsMonitoring:
Type: AWS::ApplicationInsights::Application
Properties:
ResourceGroupName:
Fn::Join:
- ''
- - ApplicationInsights-SAM-
- Ref: AWS::StackName
AutoConfigurationEnabled: 'true'
DependsOn: ApplicationResourceGroup
Outputs:
# ServerlessRestApi is an implicit API created out of Events key under Serverless::Function
# Find out more about other implicit resources you can reference within SAM
# https://github.com/awslabs/serverless-application-model/blob/master/docs/internals/generated_resources.rst#api
HelloWorldApi:
Description: API Gateway endpoint URL for Prod stage for Hello World function
Value: !Sub "https://${ApiGatewayApi}.execute-api.${AWS::Region}.amazonaws.com/prod/"
OpenSearchAPIFunction:
Description: Hello World Lambda Function ARN
Value: !GetAtt OpenSearchAPIFunction.Arn
OpenSearchAPIFunctionIamRole:
Description: Implicit IAM Role created for Hello World function
Value: !GetAtt OpenSearchAPIFunctionRole.ArnHere is the snippet for the actual Lambda function that gets invoked based on API gateway event. You could use various query DSL strategies to perform a full text search and in this case, match_phrase_prefix query worked fine for me.
import json
import boto3
from opensearchpy import OpenSearch, helpers
def lambda_handler(event, context):
domain_endpoint = 'YOUR_DOMAIN_ENDPOINT'
index = 'cloudysky-cms-data'
queryString = event['queryStringParameters']['q']
# Get Secrets from Secrets Manager
def get_secrets(secret_name):
region_name = "us-east-1"
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=region_name
)
get_secret_value_response = client.get_secret_value(
SecretId=secret_name)
return get_secret_value_response
# Get Connection String
def get_connection_string():
user = get_secrets(secret_name="os-username")['SecretString']
password = get_secrets(secret_name="os-password")['SecretString']
connection_string = "https://{}:{}@{}:443".format(
user, password, domain_endpoint)
return connection_string
# Search Documents within OpenSearch
def search_documents(data):
connection_string = get_connection_string()
client = OpenSearch([connection_string])
response = client.search(index=index, body={
"query": {
"match_phrase_prefix": {
"title": {
"query": data,
"slop": 3,
"max_expansions": 10,
}
}
}
})
return response
response_data = search_documents(queryString)
hits = response_data['hits']['hits']
response = {
"statusCode": 200,
"headers": {
"Access-Control-Allow-Origin": '*'
},
"isBase64Encoded": False
}
response['body'] = json.dumps(hits)
return response
# return {
# "statusCode": 200,
# "body": json.dumps({
# "message": queryString,
# }),
# }If you have followed above steps correctly, you would end up with a API URL like mine :- https://*****.*****/api/opensearch-results?q=DevOps
This integrated approach offers several benefits. It allows you to provision and manage your OpenSearch cluster and associated resources in a consistent and repeatable manner. API Gateway provides a secure and scalable interface for accessing the OpenSearch data, ensuring fine-grained control over access permissions and enforcing security measures. Lambda functions offer flexibility and extensibility, enabling you to implement custom business logic or data transformations as needed.
By combining IaC, API Gateway, and Lambda, you can streamline the provisioning of OpenSearch clusters, enhance security, and provide a scalable and controlled API interface for accessing and managing your data.
Sandeep Yaramchitti
- Bringing my ideas into life through Code.
ALL SYSTEMS ONLINE